距离上一篇《好地段是怎么选出来的-从北京地铁看区域的重要性》已经过去八年有余,一直念叨着重新更新一下北京的地铁数据。话说 deadline 是第一生产力,春节前立了 flag,今天利利索索地把它拔了。
读者可以从本文得到什么信息呢?
- 从全新的 2024 年北京地铁规划,识别以北京(地铁)交通便利视角的关键区域。
- 获取这些关键地段的二手房产信息,通过供给量和均价两个角度,帮助大家找到可能的价值洼地。
1. 构建地铁的网络
首先重新认识一下 2024 年的北京地铁线路规划图:
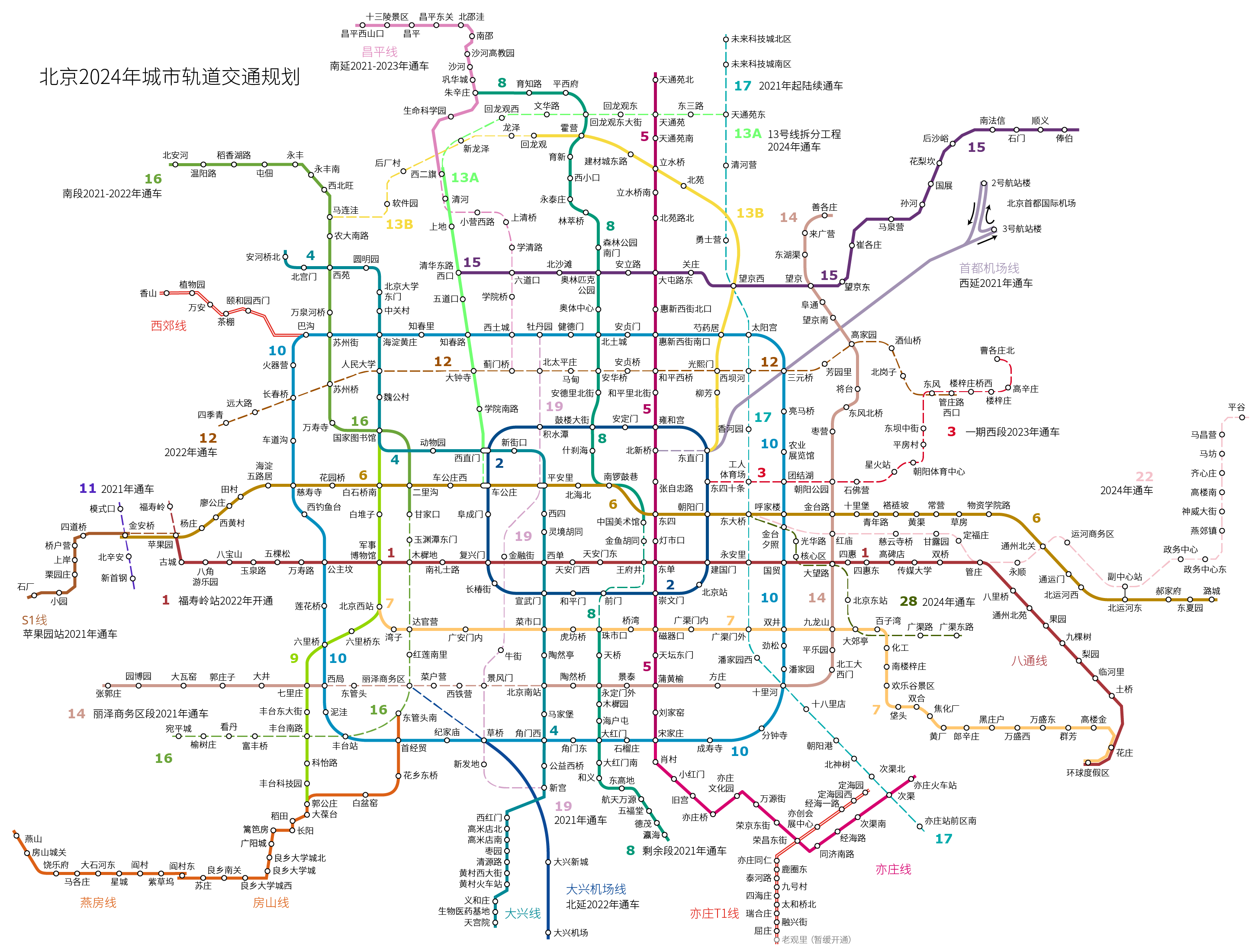
至 2024 年全北京一共 422 个地铁站点(约数,有些懒得调整,比如 13 号线会拆分,没有做调整)。回想二十年前北京只有1号线、2号线两条地铁线,北京的发展速度也确实让人咂舌(回龙观最初房价 2000,一声叹息)。
这 422 个站点信息如何获得,可以分为两步来进行:
- 通过高德地图的网页中获取正在运营地铁站点的经纬度和隶属信息。
- 补齐缺失了 8 号线的中段,14 号线中段,16 号线南段信息;补充了 3、11、12、17、19、22、28 号线的全部站点信息(无经纬度)
高德地图不但提供了北京地铁数据,还非常贴心地提供了上海、广州、武汉、深圳等地地铁运营数据。一段很短的定向爬虫,拿下这份数据(示例):
| names | terminal | longitude | latitude |
|---|---|---|---|
| 亦庄线 | 荣昌东街 | 39.782832 | 116.521688 |
| 亦庄线 | 同济南路 | 39.772962 | 116.539901 |
| 亦庄线 | 经海路 | 39.783673 | 116.562321 |
| 亦庄线 | 次渠南 | 39.795118 | 116.581357 |
| 亦庄线 | 次渠 | 39.803500 | 116.591502 |
| 亦庄线 | 亦庄火车站 | 39.812607 | 116.601913 |
这里面有一些细节,比如地铁网络的边是有权重的。一种做法是将站点和站点之间的权重用两个站点距离的倒数来度量(距离越近关联性性越强),没有经纬度的站点之间的权重统一设置为全部边的平均值。但考虑地铁出行的实际体验,以及真实的两站之间的关联性(想象一下在知春路,从十号线换乘十三号线的换乘感受),这个距离一般还真不一定是关键因素,所以我粗暴地去掉了边权重这个指标,认为两站之间的权重一致。
有了站点数据后,就可以构建北京地铁的网络拓扑图,进而度量和描述每个地铁站在全网络的作用。可问题又来了,我们应该用什么指标来衡量呢?重新查阅了相关资料后,了解到中心度大概有三十几种,有些还不太好解释,所以度量方式依然采用了《好地段是怎么选出来的-从北京地铁看区域的重要性》中的三个指标:
- Betweenness centrality:如果地铁网络中有这样一个站点 A,其他的站点都要通过 A 才能到达其他的站,那么这个站点越重要。想象极端的情况,如果没有了站点 A,你需要绕行很大一段,才能从一个站点到达另一个站点。
- PageRank centrality:如果同 A 站点连接的站点都非常好,那么物以类聚,A 站点也应该是一个很好的站点。简单地可以理解为 A 点的重要程度是周围连接点重要程度的加权。
- Closeness centrality:如果从地铁网络中 A 点,到所有其他地铁站的“最短距离”的和最小的话,那这个站点一定是最便捷的,它反映的是网络节点 A 到其他节点的平均最短距离。
这个工作准备结束后,我们计算出了 422 个站点的三个核心指标:
| betweenness | pagerank | closeness | |
|---|---|---|---|
| 巴沟 | 2080.0000 | 0.0022162 | 6122 |
| 苏州街 | 2490.0000 | 0.0020500 | 5712 |
| 海淀黄庄 | 3942.2897 | 0.0035418 | 5304 |
| 知春里 | 815.0526 | 0.0018323 | 5323 |
| 知春路 | 6412.0152 | 0.0034080 | 5001 |
| 西土城 | 1178.9848 | 0.0018085 | 5044 |
| 牡丹园 | 2657.0143 | 0.0025725 | 4818 |
| 健德门 | 2124.6522 | 0.0017950 | 5074 |
| 北土城 | 4253.7759 | 0.0033441 | 5084 |
| 安贞门 | 1738.8012 | 0.0017301 | 5136 |
直接描述 422 个站点信息是没有意义的,我们需要将他们聚成几个类,辅助我们理解这些站点的表现。
2. 相似地域的聚类
聚类是一种统计方法。如果我们将样本分为多个类,聚类方法可以保证类和类之间的差异度足够大,而类间的差异则足够小。这样我们就可以只看这几个类,他们代表所有样本信息。
如果每个站点可以用以上三个指标来表达,那这 422 个地铁站点(区域)可以简单的认为是几类?这个问题统计学家已经给我们很多方法了,比如 R. Tibshirani, G. Walther, and T. Hastie (Standford University, 2001) 给的 Gap Statistic Method 就很好用,原理这里不介绍了,直接看结果:

建议是 1 类,这显然不合理,我们不能不分类。从图上看,如果切分为 5 类也是很不错的选择,所以将这 422 个站点分为五类看效果:
> size <- 5
> k <- kmeans(scale(dat[,-1]), size)
> k$centers # 观察中心点
b PR c
1 -0.3289514 -0.7113196 -0.5270072
2 -0.4928851 -0.0680553 2.1105316
3 -0.3164911 -0.1204436 0.5436801
4 0.4761036 1.5785205 -0.6878083
5 2.9584748 0.8770382 -0.9454840
> k$size # 类大小
[1] 165 47 113 70 27从刚才三个指标的描述上看,betweenness 和 page rank 越大越好,closeness 我取了倒数,越小越好。从中心点上看,第 4 类(有 70 个)和第 5 类(有 27 个)是我们需要重点关注的站点类别。这两类的三个指标表现都是最优秀的,当然第 5 类显著好于第 4 类。
如果将所有的站点进行(主成分)二维展示的话,是这个样子的:
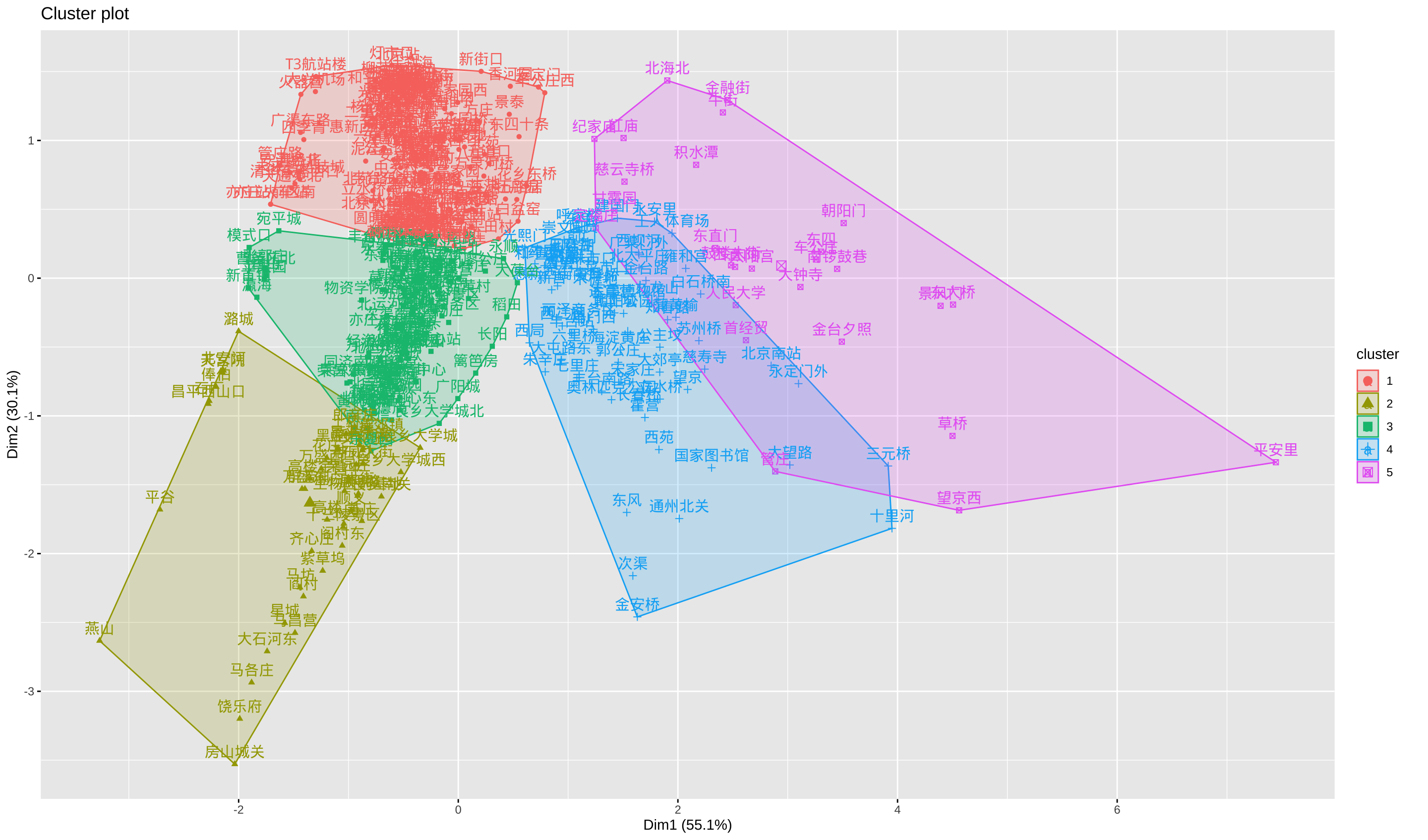
为了更直观,我将这两类的所有站点,按照 betweenness 和 page rank 两个值做了可视化:

- 两类的 betweeness 和 page rank 都很高
- 第 4 类的 page rank 更高,第 5 类的 betweeness 更高(网络中的瓶颈点)
3. 寻求价值洼地
这 97 个站点占据了全部 422 个地铁站点中相对关键的位置,如果我们还能够知道这些区域的房产均价和二手房供应量信息,那大家上车的姿势就可以确定了。
这个数据可以从贝壳网页端的 API 中获取(很容易找到)。这里忍不住要赞一下贝壳,二手房的基础数据整理的非常完备!比如这是获取的一个片段数据(西二旗附近):
| name | price | count | longitude | latitude |
|---|---|---|---|---|
| 领秀慧谷C区 | 57595 | 23 | 116.3105 | 40.10650 |
| 领秀慧谷B区 | 48309 | 11 | 116.3087 | 40.10320 |
| 领秀慧谷D区 | 55930 | 8 | 116.3065 | 40.10525 |
| 领秀慧谷A区 | 48422 | 7 | 116.3106 | 40.10314 |
| TBD住总万科天地 | 42256 | 3 | 116.3225 | 40.10905 |
| 领秀慧谷D2区 | 51769 | 1 | 116.3049 | 40.10625 |
有个两个小细节:
- 我为了保证步行 10 分钟内能走到地铁站,所有获取的小区是在该站点纬度正负 0.02201548/4 区间,经度正负 0.04132205/4 区间。
- 该地域的二手房均价我采用的是区域房价的加权平均值,并未考虑几居室分布的问题(贝壳暂时只有这个数据)。
将区域的二手房均价和二手房供应量放在一张图上就清楚很多了:
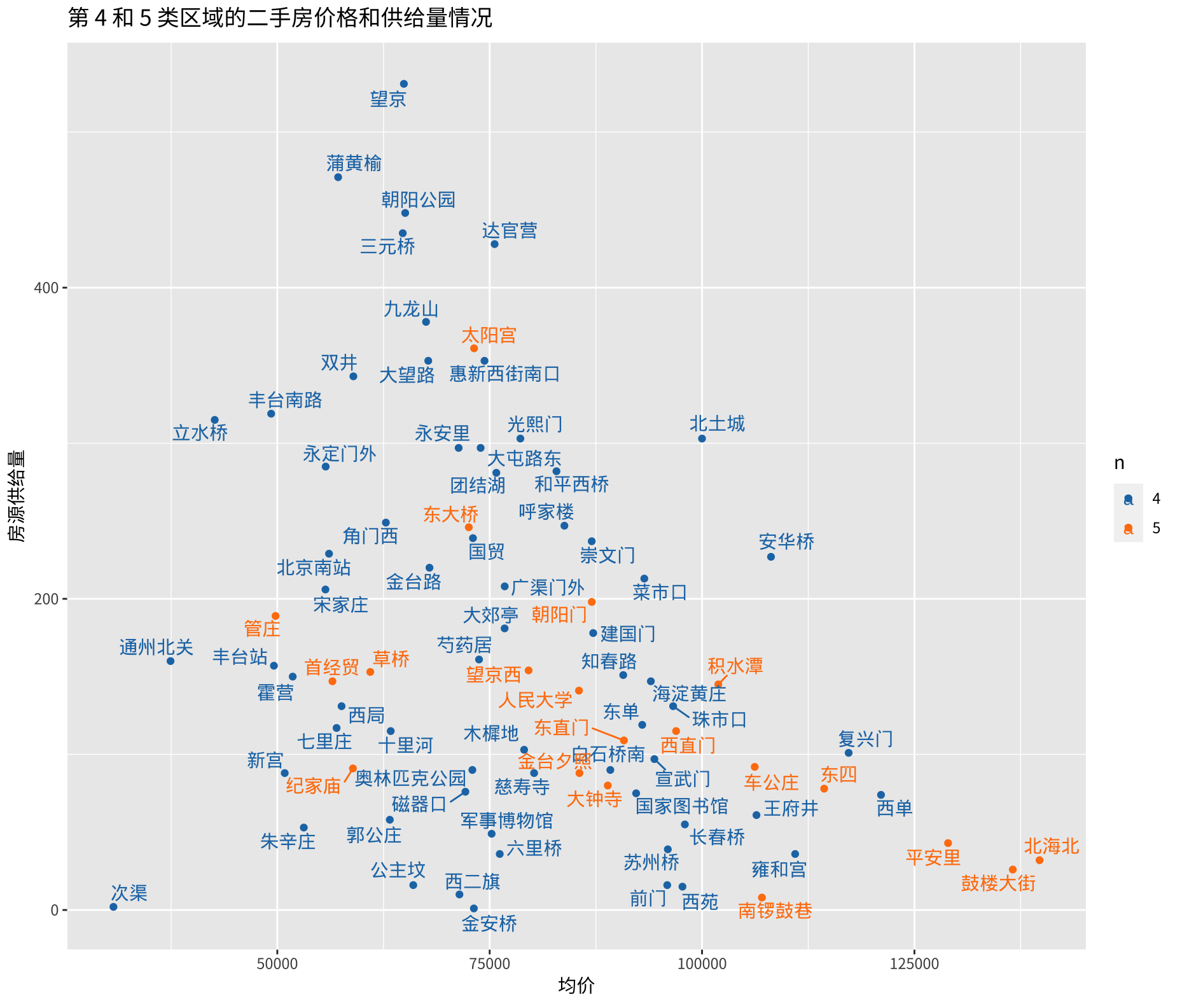
这张图的信息量有点略大,比如:
- 有些二环外,如东城区的一些地方也不是不能考虑,当然还要具体看楼龄和学区情况;
- 立水桥、九龙山这些地方从来都不在视野之内,未来应该多给一些关注;
- 首经贸、管庄、草桥隶属于第五类,本应属于高攀不起的那一波,但可以再咂摸咂摸;
- 200 套以上,均价在 75000 以下在图的左上方,说明的是选择空间大,预算相对可控;
- 可以把具体某个站点的数据单拎出来细看,包括三个核心中心度指标和二手房小区信息。
然,每位看官关注点必然不同,我也就能帮到这里了。未来不论各位是新上车还是需求改善,有行动也记得给我一些反馈。
获取数据,数据预处理,作图、注释,总计代码量共计 190 行,见后文。全文完毕,收工!
4. 代码
## 获取北京地铁数据,源自于`http://map.amap.com/subway/index.html`
library(jsonlite)
library(magrittr)
library(igraph)
library(dplyr)
url <-
'http://map.amap.com/service/subway?_1612711668721&srhdata=1100_drw_beijing.json'
x <- fromJSON(url)
names(x) # x$l 是关键数据对象
subwaynames <- rep(x$l$ln, times = sapply(x$l$st, nrow))
subwaydata <- do.call(rbind, x$l$st)
titude <- do.call(rbind, strsplit(subwaydata$sl, ','))
## 得到各个站点的名称和经纬度,包括隶属于几号线
subway <-
data.frame(
subwaynames,
terminal = subwaydata$n,
longitude = titude[, 2],
latitude = titude[, 1]
)
## 构造函数处理 json 里面的数据,得到带边权重的 graph
weight_graph <- function(x) {
line_names <- x$terminal
n <- length(line_names)
a <- 1:(n - 1)
b <- 2:n
m <- cbind(a, b)
distance <- x[, c('longitude', 'latitude')] %>% dist()
weight_g_df <-
data.frame(from = line_names[a],
to = line_names[b],
w = as.matrix(distance)[m])
return(weight_g_df)
}
## 获得构建北京地铁 graph 的 data frame
d1 <-
by(subway[, 2:4], subway$subwaynames, weight_graph) %>% do.call(rbind, .)
mean_weight <- mean(d1$w)
## d1[grep('16号线', rownames(d1)),] # 看是否有遗漏
## 增加 2024 年未来规划的线路
## 包括补充了 8 号线中段,14 号线中段,16 号线南段
## https://upload.wikimedia.org/wikipedia/commons/a/a2/Beijing-Subway-Plan.png
line3 <- c('东四十条', '工人体育场', '团结湖', '朝阳公园', '石佛营', '星火站', '朝阳体育中心', '平房村', '东坝中街', '东风', '楼梓庄桥西', '楼梓庄', '高辛庄', '曹各庄北')
line8 <- c('中国美术馆', '金鱼胡同', '王府井', '前门', '珠市口')
line11 <- c('模式口', '金安桥', '北辛安', '新首钢')
line12 <- c('四季青', '远大路', '长春桥', '苏州桥', '人民大学', '大钟寺', '蓟门桥', '北太平庄', '马甸', '安华桥', '安贞桥', '和平西桥', '光熙门', '西坝河', '三元桥', '芳园里', '高家园', '酒仙桥', '北岗子', '东风', '管庄路')
line14 <- c('西局', '东管头', '丽泽商务区', '菜户营', '西铁营', '景风门', '北京南站', '永定门外')
line16 <- c('国家图书馆', '二里沟', '甘家口', '玉渊潭东门', '木樨地', '达官营', '红莲南里', '丽泽商务区', '东管头南', '丰台站', '丰台南路', '富丰桥', '看丹', '榆树庄', '宛平城')
line17 <- c('未来各科技城', '天通苑东', '清河营', '勇士营', '望京西', '太阳宫', '西坝河', '香河园', '工人体育场', '东大桥', '永安里', '广渠门外', '潘家园西', '十里河', '十八里店', '朝阳港', '北神树', '次渠北', '次渠', '亦庄站前区南')
line19 <- c('牡丹园', '北太平庄', '积水潭', '平安里', '金融街', '牛街', '景风门', '草桥', '新发地', '新宫')
line22 <- c('东大桥', '金台夕照', '红庙', '慈云寺桥', '甘露园', '定福庄', '管庄', '永顺', '通州北关', '运河商务区', '副中心站', '政务中心', '政务中心东', '燕郊镇', '神威大街', '潮白大街', '高楼', '齐心庄', '马坊', '马昌营', '平谷')
line28 <- c('东大桥', '金台夕照', '光华路', '核心区', '大望路', '北京东站', '大郊亭', '广渠路', '广渠东路')
line_graph <- function(x, w = mean_weight){
n <- length(x)
a <- 1:(n-1)
b <- 2:n
return(data.frame(from = x[a], to = x[b], w = w))
}
l3 <- line_graph(line3)
l8 <- line_graph(line8)
l11 <- line_graph(line11)
l12 <- line_graph(line12)
l14 <- line_graph(line14)
l16 <- line_graph(line16)
l17 <- line_graph(line17)
l19 <- line_graph(line19)
l22 <- line_graph(line22)
l28 <- line_graph(line28)
## 合并无权重的图数据
dd <- unique(rbind(d1, l3, l8, l11, l12, l14, l16, l17, l19, l22, l28)[, 1:2])
g <- graph_from_data_frame(dd, directed = FALSE)
## E(g)$weight <- sqrt(1/subway_graph_dataframe$w)
## 观察中心度相关指标是否合理
data.frame(name = V(g)$name, v = betweenness(g)) %>%
arrange(desc(v)) %>% head(20)
data.frame(name = V(g)$name, v = 1 / closeness(g)) %>%
arrange(desc(v)) %>% tail(20)
## 聚类,确定聚多少类
library(ggplot2)
library(ggsci)
library(ggrepel)
library(factoextra)
library(cluster)
set.seed(123)
dat <- data.frame(
name = V(g)$name,
b = betweenness(g),
PR = page_rank(g)$vector,
c = 1/closeness(g)
)
gap_stat <- clusGap(scale(dat[,-1]), FUN = kmeans, nstart = 25, K.max = 10, B = 50)
fviz_gap_stat(gap_stat)
size <- 5
k <- kmeans(scale(dat[,-1]), size) # 每次结果可能略有不同
k$centers # 观察中心点
k$size # 类大小
fviz_cluster(k, data = scale(dat[,-1]))
k4 <- data.frame(n = V(g)$name, k = k$cluster) %>% subset(k == 4)
k5 <- data.frame(n = V(g)$name, k = k$cluster) %>% subset(k == 5)
## 绘制第一类和第二类的 betweeness 和 PageRank 图
library(showtext)
showtext_auto()
font_add("Noto Sans SC", "/Users/liusizhe/Library/Fonts/NotoSansSC-Regular.otf")
p4 <- dat[dat$name %in% k4$n,] %>%
ggplot(aes(b, PR, label = name)) +
geom_point(color = "red") +
geom_text_repel() +
theme(text = element_text(family='Noto Sans SC')) +
ggtitle("k = 4") +
theme(axis.text.y=element_text(angle = 90, vjust = 0.5))
p5 <- dat[dat$name %in% k5$n,] %>%
ggplot(aes(b, PR, label = name)) +
geom_point(color = "red") +
geom_text_repel() +
theme(text = element_text(family='Noto Sans SC')) +
ggtitle("k = 5") +
theme(axis.text.y=element_text(angle = 90, vjust = 0.5))
library(gridExtra)
grid.arrange(p4, p5, nrow = 1)
## 从贝壳获取房源和价格信息,来定义该区域是否有价值洼地。
## 需要看附近房价的地铁站
subway <- unique(subway[, -1])
k4_5 <- rbind.data.frame(k4,k5)
names(k4_5) <- c('terminal', 'n')
subway_price_list <- inner_join(subway, k4_5)
lat_minmax_diff <- 0.02201548/4 # 经纬度查询数据的区间
longi_minmax_diff <- 0.04132205/4
## 构造获取贝壳的区域数据源
price <- list()
bubbleList <- list()
steps <- nrow(subway_price_list)
for (i in 1:steps) {
longitude <- subway_price_list[i, 'longitude'] %>% as.numeric()
latitude <- subway_price_list[i, 'latitude'] %>% as.numeric()
url <-
sprintf(
"https://map.ke.com/proxyApi/i.c-pc-webapi.ke.com/map/bubblelist?cityId=110000&dataSource=ESF&condition=&id=&groupType=community&maxLatitude=%s&minLatitude=%s&maxLongitude=%s&minLongitude=%s",
longitude + lat_minmax_diff,
longitude - lat_minmax_diff,
latitude + longi_minmax_diff,
latitude - longi_minmax_diff
)
house_raw_data <- fromJSON(url)
bubbleListData <-
house_raw_data$data$bubbleList[, c('name', 'price', 'count', 'longitude', 'latitude')]
bubbleList[[i]] <- bubbleListData
ave <-
bubbleListData %>%
transform(price = as.numeric(price)) %>%
summarise(aveprice = round(sum(price * count) / sum(count), 0),
countsum = sum(count))
price[[i]] <- ave
Sys.sleep(runif(1, 2, 3))
cat('This is the', i, 'step of', steps, 'total steps', '\n')
}
price_count <- price %>% do.call(rbind, .) %>%
data.frame(subway_price_list) %>%
mutate(n = as.character(n))
ggplot(price_count, aes(aveprice, countsum, color = n, label = terminal)) +
geom_point() +
geom_text_repel() +
theme(text = element_text(family='Noto Sans SC')) +
scale_color_d3() +
ggtitle("第 4 和 5 类区域的二手房价格和供给量情况") +
xlab('均价') +
ylab('房源供给量')